
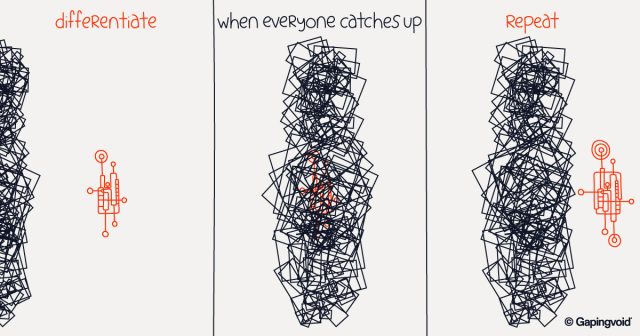

America’s Founding Mother

The First Rule of Fight Club

The Moon was Never the Point
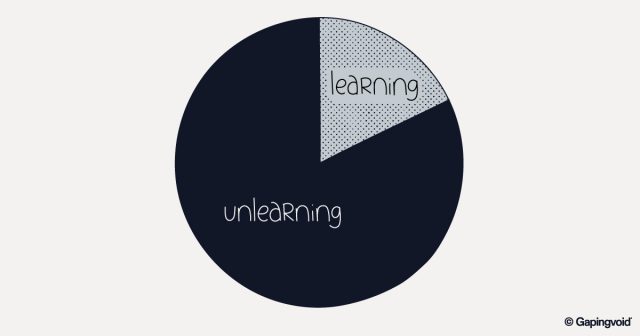
What Viking Cuisine Can Tell Us About Innovation

Mommy, Where Does Meaning Come From?
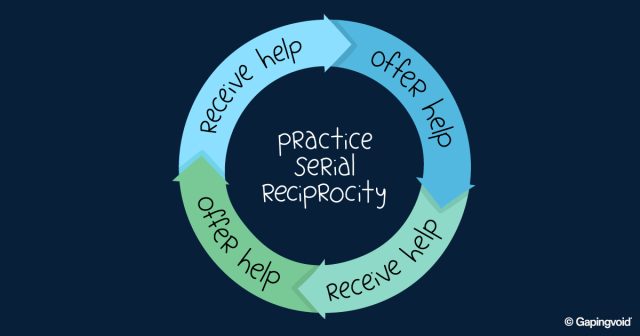
You Scratch My Back, I’ll Scratch Yours

Meliora
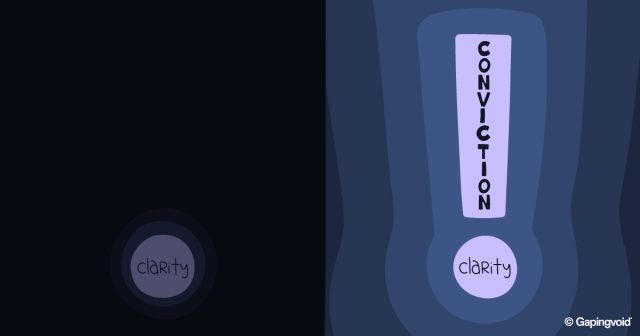
Aim
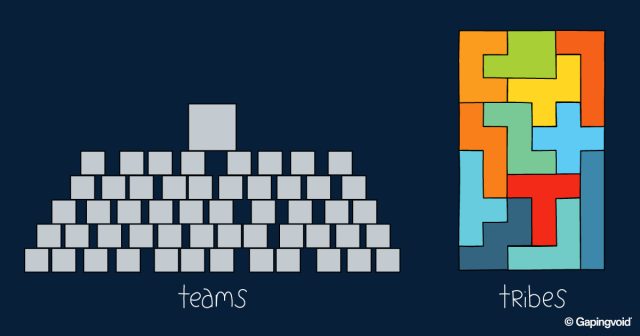
Who Knows What

Beyond Glamour: The Staples Baddie

What the 19th Century Socialite & Modern Day Host Teach Us About Leadership
- 1
- 2
- 3
- …
- 398
- Next Page »